1 Institute of Computing Technology, Chinese Academy of Sciences2 University of Chinese Academy of Sciences3 School of Advanced Interdisciplinary Sciences, UCAS 4 Cardiff University5 Kling Team, Kuaishou Technology6 Hong Kong University of Science and Technology
Figure 1: Examples synthesized by CameraSquad. Given an input video and several sets of target camera parameters, CameraSquad generates precise rendering results along specified trajectories while maintaining scene consistency across different trajectories. Multi-view content-consistent dynamic point clouds can be back-projected from the results.
Abstract
Camera-controlled video generation is valuable for applications ranging from visual design to providing 2D supervision for 4D generation tasks. However, existing approaches are limited to single-trajectory generation, forcing users to process multiple trajectories in separate batches. This serial inference introduces content inconsistencies across viewpoints due to the inherent randomness of diffusion models. Explicit point cloud methods can only partially address this problem, as single-viewpoint back-projection suffers from sparsity and depth estimation errors. We propose CameraSquad, a multi-trajectory camera control framework that supports both single-trajectory and parallel multi-trajectory generation. Our method achieves precise camera control while preserving input video content through decoupled content and camera control mechanisms. To ensure viewpoint consistency in multi-trajectory mode, we design a dual-mode cross-view attention mechanism that maintains consistency across parallel trajectories while guaranteeing camera control precision. Extensive experiments demonstrate that CameraSquad achieves competitive performance in camera control accuracy, consistency maintenance, and generation quality compared to existing approaches.
Method
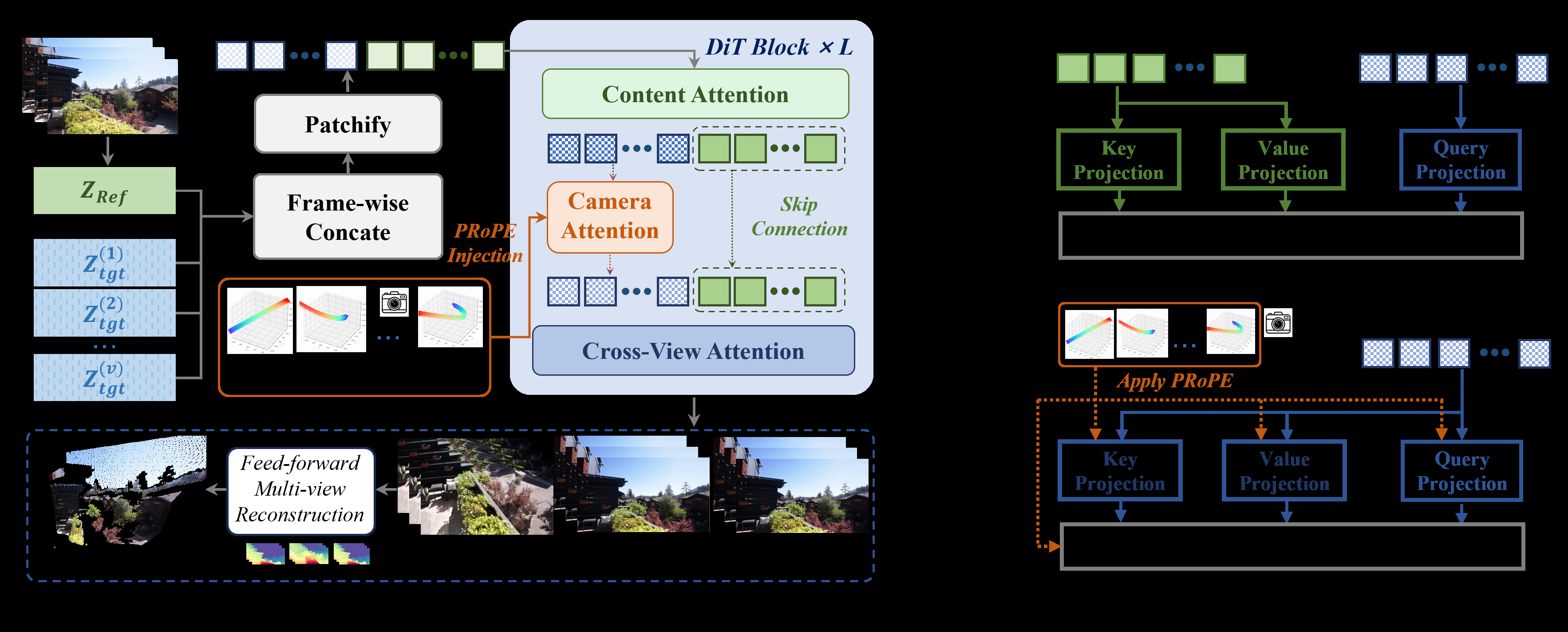
Figure 2: Overview of CameraSquad. (a) The self-attention layers are adapted into content attention, and PRoPE is employed to provide fundamental single-trajectory camera control. (b) A Dual-Mode Cross-View Attention mechanism comprising CVA-α for subject consistency and CVA-β for relative perspective accuracy.
🔬
Camera & Content Decoupled Attention
We repurpose DiT's original 3D self-attention as Content-Attention to preserve video content, and build a separate Camera-Attention pathway using the PRoPE mechanism. PRoPE encodes camera intrinsics and extrinsics into attention Q/K/V transformation matrices via projection geometry, enabling precise camera control without compressing to 1D values.
🎯
Dual-Mode Cross-View Attention
CVA-α ensures content consistency: reference video tokens provide K/V while each trajectory's noisy tokens serve as Q, making tokens from the same frame across different views mutually visible. CVA-β ensures geometric consistency: it repurposes PRoPE spatial attention from "along frame dimension" to "along view dimension", enabling multi-view geometric supervision.
🏗
Point Cloud Back-Projection
Using Depth Anything 3 (DA3) for multi-view depth estimation, CameraSquad back-projects content-consistent multi-view frames into dynamic point clouds. The resulting point clouds are larger, finer, and more complete than single-view methods, providing high-quality 3D world states for downstream 4D reconstruction.
Results
Single-Trajectory Comparison
Figure 3: Qualitative comparison of single trajectory video synthesis. CameraSquad achieves competitive generation quality compared to existing state-of-the-art camera control methods.
Multi-View Point Cloud Reprojection
Figure 4: Qualitative comparison of multi-view point cloud reprojection. CameraSquad preserves pixels across varying perspectives, while baseline methods exhibit varying degrees of loss in background or subject regions.
6-Trajectory Visualization
Figure 7: Visualization of 6-trajectory generation results. CameraSquad enables synchronous generation of up to 6 trajectories, consistently producing stable outputs for both human and landscape videos.
Multi-Trajectory Comparison
Figure 6: Qualitative comparison of multi-trajectory video synthesis with existing state-of-the-art camera control methods.
More Single-Trajectory Results
Figure 8: More results of qualitative comparison of single trajectory video synthesis.
Video Results
Demo videos will be added soon.
Citation
@article{xu2026camerasquad,
title = {CameraSquad: Achieving Content Consistency in Parallel Multi-Trajectory Camera-Controlled Video Generation},
author = {Xu, Zhufeng and Gao, Xuan and Deng, Bailin and Ding, Yikang and Liu, Xiaoqiang and Zhang, Haoxian and Wan, Pengfei and Fu, Hongbo and Gao, Lin},
journal = {ACM Transactions on Graphics},
year = {2026},
publisher = {ACM}
}